.webp?width=1220&height=1090&name=Osano-guarantee-seal%20(1).webp)

This blog aims to illustrate pain points we've run into at various stages of development. We hope to help engineers and product folks overcome similar obstacles by explaining how we overcome our own.
A good problem to have: Scaling our Consent Management platform API
Osano started in 2019 with no product and no customers. As of October 2021, our Consent Management Platform (CMP) API receives 21,000,000 requests per day, or roughly 250 requests a second. Not too bad for our size. It's remarkable if you consider each one of those requests as a human clicking a button on a website.
Cookie consent management is our main product, and data privacy is our main business. At the surface, the CMP provides customers with a simple website banner to gather consent for cookies on their websites. On a deeper level, we provide our customers with compliance to the various privacy laws scattered across the globe, be it the European Union's General Data Protection Regulation or the California Consumer Privacy Act. All of these regulations have rules on how that simple banner for cookie consent must be presented and how to deal with the user's data. It's all rather complicated.
But that complicated nature is Osano's specialty, and we even have a pledge to cover costs if our customers are fined under those regulations. This value proposition and fantastic customer service are what spurs our amazing growth. But with growth comes the growing pains. From one API call per day to two hundred a second is very different. We built and rebuilt our systems to face this growth.
Requirements and expectations
The overall architectural design of the consent API, as we call it, hasn't changed much since the beginning of our engineering journey. That consistency is due to two factors: consent data requirements and user/customer expectations.
Data Requirements
We believe that data is the lifeblood of software engineering. Every design should revolve around your data needs because, in the end, the data is what adds value to the company. Osano's consent data is sacred, and rules exist around handling that data. The following three rules dictate how we must approach the problem of processing a user consenting to cookies.
- Consent event data is simple.
- Consent event data is immutable.
- Every change to a user's consent is a new event linked to a previous event.
The data exchanged between the consenting user and Osano needs to be as simple as possible. Users come from all over the world and from many different devices: mobile phones, laptops, or anything that can render a website. We built our system with millions of users from the get-go not due to hubris but as a protection. Large amounts of data bring down nations. That's a DDoS attack. We don't want millions of users a day sending us massive payloads. We'd be ruined. We also don't want to store consent events of that size. It's not feasible.
The consent event is more or less an agreement between the user and the website that uses Osano's consent manager. We want to make sure that accepting the cookies on the website is stored for both the user and the website. Once this event is in our system, it cannot be changed. In common engineering terms, it's now immutable. Immutability has great benefits for the traceability of events and code simplicity. Why? See functional programming. Data that can change over time is hard to work with and introduces bugs.
Our users' consent data cannot change, but what if we need to change it? We just create a new consent event for that user. We now should link the previous event and the new event for traceability. At any point in time, the user and the website can know what a user's preferences were and are. Our data is now the story and the truth if someone doubts it. We can prove what happened.
Expectations
Software architecture is the pipeline the data travels through to be helpful for the end customer. Architectures can be complex, massive and expensive depending on the expectations set by you to the customer. Twitter's architecture must handle millions of tweets a second. Twitter's users expect their tweets to go out to millions of people in almost real-time. Google's architecture must take billions of searches an hour. They expect search results to be quality and return almost instantly. Twitter and Google built their architectures around customer expectations, and we do the same. We have three expectations: two from the customers and one from the consenting users.
Our customers expect a user's cookie consent to be recorded and kept safe. This is the rule we live by. We must maintain data integrity. If a customer or user needs to see that data, we MUST be able to retrieve it. The second expectation is the CMP should never affect the user experience of the customer's website. For this, we need to have incredibly fast API calls and never block intended functionality on the website.
The user who is consenting has an expectation that they don't even register. Once that "I agree" button is pressed, they should no longer need to think about the action.
Our Consent API architecture is as simple as possible and no more to achieve the expectations.
The architecture
The difficulty of the problem should be apparent. How do we meet the expectations of the customers and users, so our product is profitable for us? Answer: Keep the API simple.
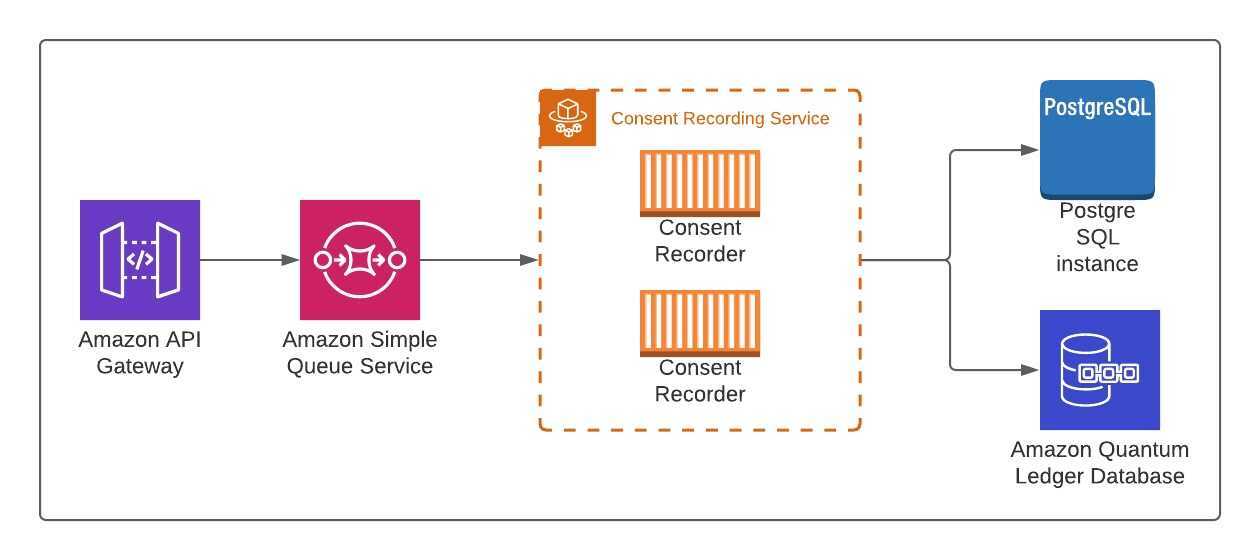
Our stack
- AWS API Gateway
- AWS Simple Queue Service
- AWS Elastic Container Service
- AWS Fargate
- Docker
- NodeJS
- AWS Autoscaling Alerts
- AWS Aurora PostgreSQL
- AWS Quantum Ledger Database
There is no secret sauce or an exotic technique used in our stack. Well, maybe AWS Quantum Ledger Database. Overall, we are using tried and tested services provided by AWS with a little of our glue here and there.
Horizontal
Horizontal scalability is defined by the ability to bring up as many resources needed to process incoming data. Vertical scaling is scaling up an existing resource by adding more computing power such as a CPUs or memory. Horizontal scaling is incredibly powerful but requires decoupling of steps, so each is "pure," meaning given the same input to a step produces the same output every time. Immutability of data is an easy way to ensure this.
Putting it all together
So what does this have to do with how to meet our customers' expectations? All these pieces put together dictated the overall architecture seen in the diagram above. Every step is scalable, minimizes latencies and ensures data integrity.
Imagine user consent data as a library book the user wants to return. First, the user drops the book in the return. Our slot is a bit special, though. The slot can reject any books and validate the book is supposed to be returned to the library. The AWS API Gateway does this for us. Data comes into the gateway; the gateway authorizes, validates and does a little bit of processing to make sure the data is correct. Once our return slot (the API Gateway) is happy, it pushes the data onto a conveyor belt. It does all of this in less than 70ms on average, and the user who generated the data no longer needs to worry. They walk away, happy to know their book is returned.
The now collected data moves onto the conveyor belt, the AWS Simple Queue Service queue. Why don't we directly process the data once the user submits it? Two reasons: keeping API response times down and horizontal scalability. The data moves down the belt until a worker can process the data further. Like an assembly line, many workers pick data off the conveyor.
Each worker takes one piece of data, evaluates it, sorts it and pushes it to long-term storage. Once stored, the worker moves on to the next data available. This repeats hundreds of times a second. If there is too much data for workers to handle, we have automated systems that scale up our workforce. We also remove some workers if the amount of work is too low. Besides keeping our costs in line, this helps us deal with surges in incoming consents.
With the data processed, we have to store it. Our storage is in two places. First, the canonical storage is AWS Quantum Ledger Database (QLDB). This is a cool bit of tech. QLDB allows us to store our data about previous events of the same user. The initial consent data is stored, and any updates to the user's preferences are related to all previous consent data for that user. We can prove the changes from one data point to the next.
QLDB is great, but it's not great for searching the data. For this, we use a tried and tested database, the relational database. I won't get into relational databases but know they are lovely for searching and getting the data exactly the way you want it. There are caveats, but overall, it's great for our purposes since our data is simple.
That's the end of this pipeline, and this overall structure has proved itself time and again. But like every good time, it is starting to end. We are thinking of our next-generation pipeline.
The missteps along the way
Like every journey, we often present only the end product. I said before that the architecture hasn't changed much. That's not a lie. There are still lessons learned that should be shared and where we are going.
Validate early and validate often
The biggest struggle is dealing with bad data. Bad data can be expensive or even dangerous to a system (think SQL injections). Our first systems didn't have a lot of good validation and waited until the last minute. Our lesson is: The longer you put off validation, the more expensive it is computationally and monetarily. The two are intrinsically linked.
Lambda functions are great until they aren't
Before we used Elastic Container Service for the workers, we used AWS Lambda. Lambda is a wonderful service that works best if processing event data. Our pipeline is a perfect use case, right? Yes, it was, initially. We realized pretty quickly that the costs of lambda add up. We would have hundreds of lambda functions working on the queue but most of their time was spent waiting on the databases. This wasn't an issue when we had empty work queues as lambda costs went to zero. Once we had enough in our queue to have those 100 lambdas always working, it was better to move to ECS.
Database I/O is expensive
Expense is calculated in monetary value and in time. Databases affect both. A big consideration in software engineering is device input and output (I/O). This can be writing a file to long-term storage, a hard drive, or reading from a database. All of this is extremely expensive timewise. Often, we can't do much else until those operations are finished. This is the case for our consent data workers. They sit there for a long time (at least by programming standards) before they can finish processing the data. Each of our workers can handle about 150 events/second, and most of that time is waiting on our relational database.
The monetary expense of the database is also a problem. We currently have a rather large CPU requirement to handle all the incoming requests, and so we can handle the spikes in incoming data. As much as we like to believe that computers are cheap, they aren't once you get to the sizes we need. Overall, our current system isn't as scalable as we want. Luckily, we have a solution in the works.
The future
Today's architecture will not hold for the future. That's the truth no matter what any consultant tells you. Engineers design within constraints for the current time and place. We have to balance time, money and needs. For us, we can see the cliff of our current system. Luckily, we are months out from falling off the edge. Even more, we are doing something about it. I won't say what is here since it is still in flux.
I'm grateful for our engineering team's skills and determination and thankful that our leadership at Osano lets the engineers fix issues before they become problems. I'm also appreciative our problems are all because we are growing fast. Hopefully next year I can write an update to this post since I'm 100% sure the details will be irrelevant.
U.S. Data Privacy Checklist
Stay up to date with U.S. data privacy laws and requirements.
Download Your Copy



